Product
June 9th, 2026
13 min read
Minerva: Democratizing Data with OpenAI
Mathew Joseph
Co-Founder & CTO, Minerva
James Yu
AI Engineer, Minerva

With OpenAI, Minerva has created two revolutionary agentic systems that enable our platform to scale with the complexity of our rapidly growing customer base. We designed them to solve two core problems at scale:
- Unified data: how do we ingest and normalize bespoke company data at scale, where client database shapes and connectors are fundamentally different?
- Event intelligence: how do we train robust machine learning models to make predictions on client event feeds that vary massively across customers?
Introducing our Agentic Data Engineer (ADE) and Agentic Data Scientist (ADS). Together, they answer business questions in hours that would traditionally take teams of data engineers and data scientists weeks. Because they scale with compute rather than headcount, ADE and ADS enable us to implement quickly, even with the most complex data systems. Importantly, unlike a siloed data team or one-off software integration, our agents stay present and learn from every question they answer.
ADE and ADS have made material improvements on business outcomes and scalability for Minerva deployments by Forward Deployed Engineers (FDE):

Agentic Data Engineer
Every brand we work with arrives with its own version of the same problem: customer data scattered across a dozen systems, shaped by years of decisions that made sense at the time. One company runs Shopify and Klaviyo, another has a custom warehouse full of tables nobody outside the company fully understands and another runs the same stack with a completely different configuration and no concept of a golden record.
Before any of Minerva's models, agents or analytics can do their work, that disparate data has to be transformed into a unified, predictable structure that defines who the audience is, how people interact with the brand across web, mobile and real life exchanges and what sits in the product catalog.
The Agentic Data Engineer (ADE) is the system that performs this standardization. With OpenAI Agents SDK, ADE takes the messy, bespoke data that each client provides and normalizes while preserving the details that make each business different. It does the work of an entire data engineering team: gathering domain knowledge, learning how a client's data fits together, mapping relationships across systems and resolving dependencies to produce clean, standardized data ready for use throughout the Minerva platform.
What ADE does for brands
Every business is different, so ADE is built to discover how each business actually operates by exploring its data systems rather than making assumptions based on the platforms they use. Crucially, the complexity of ADE’s task scales with the number of columns it reasons about, not the absolute size of the data lake. A larger warehouse does not make a deployment harder—only a more intricate schema does. As a result, ADE can handle wide, complex enterprise deployments as effectively as smaller ones, regardless of the absolute volume of data behind them.

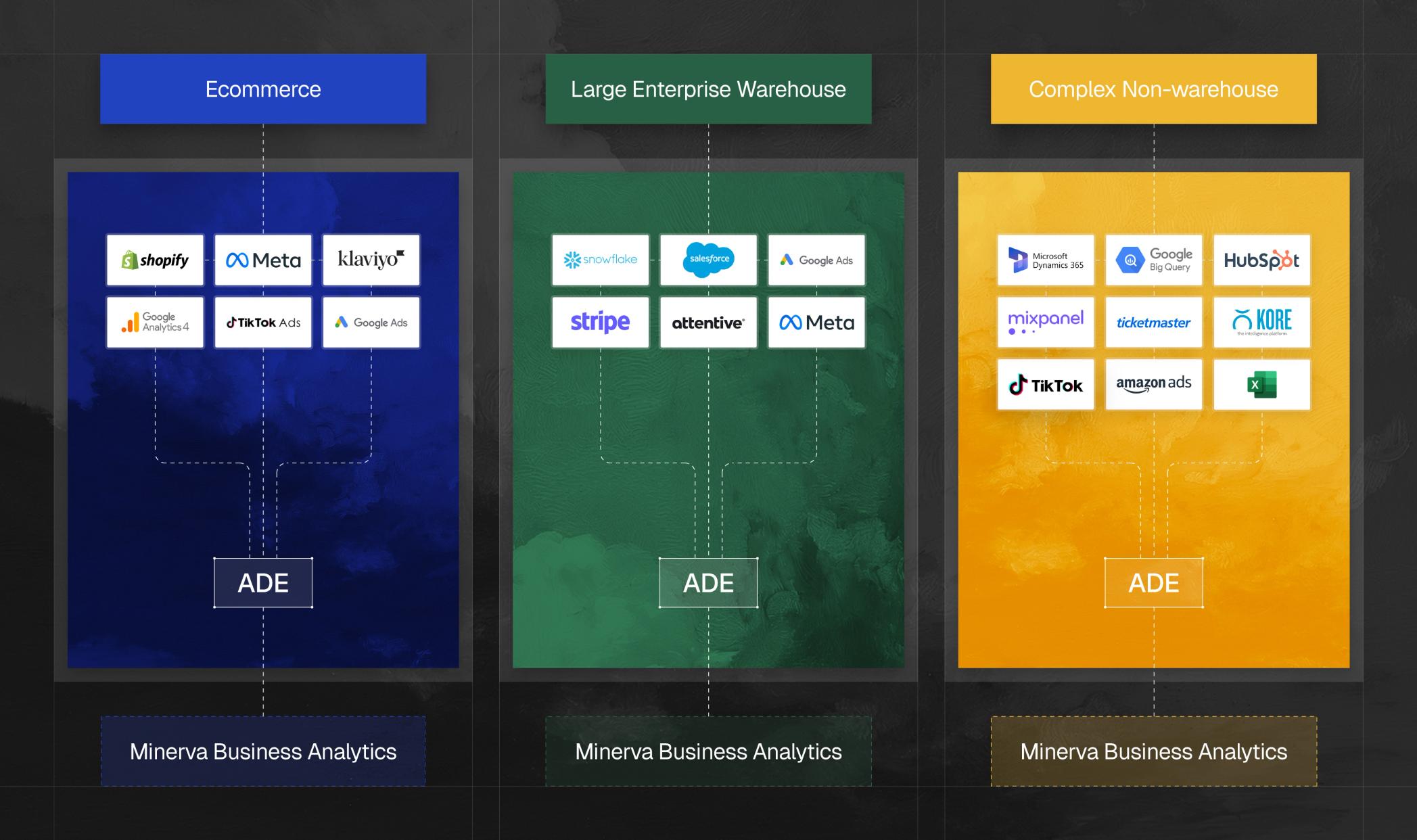
Here are a few ways this dynamic plays out in practice:
Common connectors, customized to the business: Even the most standard stack isn't truly standard. No two brands use Shopify and Klaviyo the same way. ADE works through the specifics of a brand's campaigns, custom properties and order history so that our workflows are built on the right data instead of a generic guess about how Shopify "typically" looks.
Web and app analytics: Raw event streams, like those delivered by GA4 through a warehouse export, contain no concept of a session—they're just a long list of individual events. ADE unpacks the parameters within those events and sessionizes the stream, stitching scattered interactions back into coherent user journeys. That's part of what gives us the behavioral signal behind our work on intent, conversion and churn.
Fully custom warehouses: Regardless of complexity, ADE provides the same level of insight and unification for every warehouse and connector. In one example, a travel company came to us with only their BigQuery tables: a raw bookings feed, a customer profile table and a homegrown funnel-event log. ADE worked directly on those tables, the same way it would against any standard connector.
Beyond e-commerce. ADE generalizes across industries as well. Sports franchises are a good example. ADE reads their contacts, ticket orders and sales out of a Dynamics CRM and a ticketing system, then maps all of it to the same standardized tables every other client lands in, ready for the same downstream analytics.
How it works
ADE works in three distinct phases.

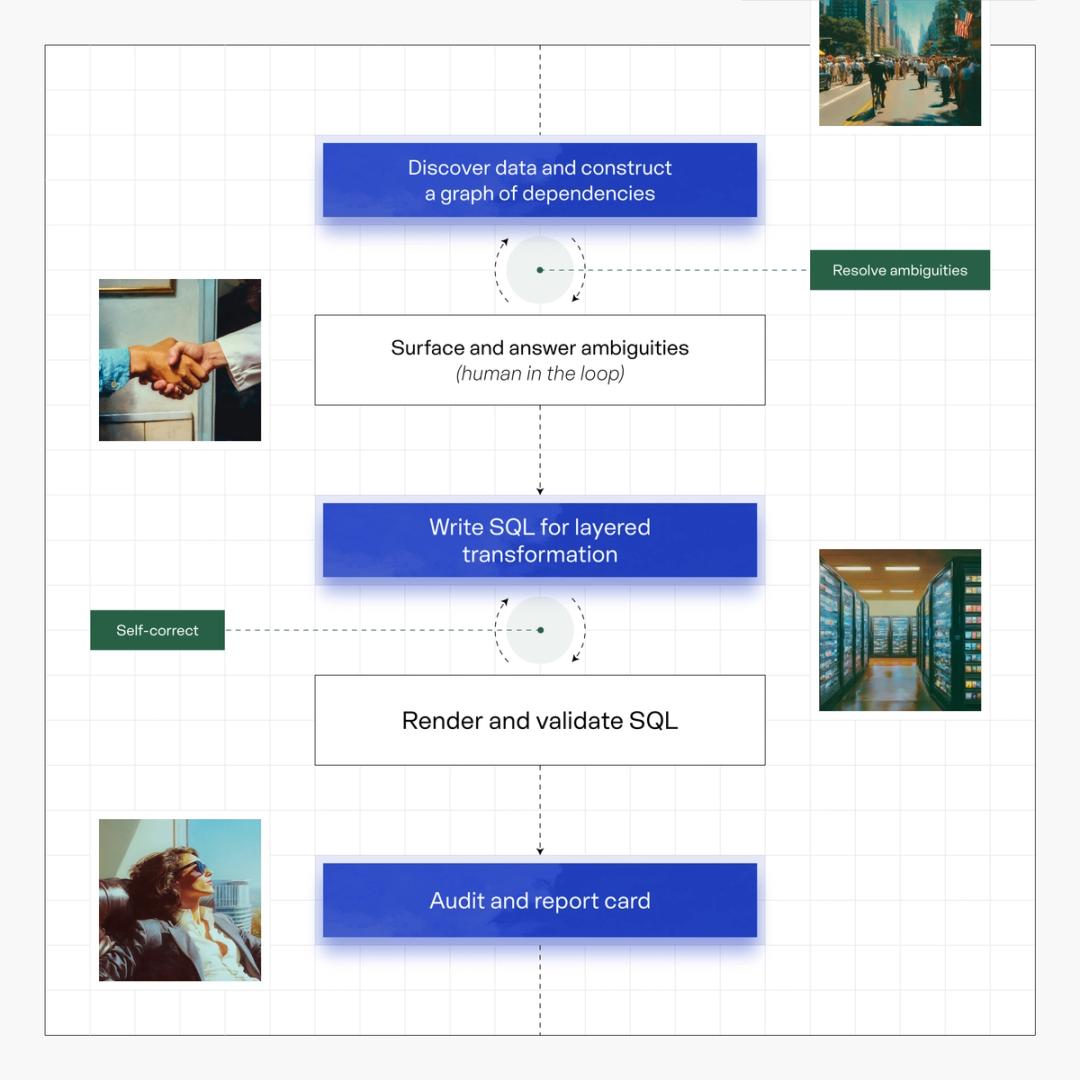
Phase one: data discovery and relationship mapping
ADE’s most important output is what we call a “contract”: a precise description of how data should flow from a customer's source tables to Minerva’s final standardized tables. To build a contract, ADE orchestrates a set of subagents that explore the client's data warehouses, discover the relationships hidden in the data and encode those relationships as a dependency graph.
Letting agents do unstructured discovery on a database invites guesswork, and guesswork is exactly what creates faulty transformations. To prevent this, we built a harness with three key features.
First, we don’t allow the agent to guess. Before a subagent decides how columns are linked to each other, it has to actually look at the data and prove it. We give it tools to inspect what's really there, and it can only lock in a connection once it's confirmed. If the agent gets something wrong, it receives immediate feedback and makes a correction.
Second, we make sure the agent builds in the right order. Some pieces of data depend on others, so they have to be understood in sequence. As an example, you can't define a customer's total order value before you've sorted out what counts as an order. One of our subagents makes sure this directionality is captured, and all dependencies are resolved before the agent builds. When the subagent realizes it needs something that hasn't been handled yet, it flags that to the ADE orchestrator to be prioritized.
Third, when a subagent runs into genuine ambiguity when making a decision, it escalates the issue to a human rather than making an uninformed guess.
Phase two: layered transformation
With the dependency graph acting as the contract, ADE builds the data pipeline as a series of transformation layers. These layers pull data from the raw sources, normalize it, resolve entities and assemble the final analytics-ready tables.
Every subagent is held to the same checks as before. Prior to committing anything, a subagent is required to profile the source columns it plans to use and confirm how they're described in the graph. Validators inspect every contribution and trigger self-correction when a syntax error surfaces.
Historically, this type of data modeling has been one of the primary barriers preventing companies from fully utilizing their own data. ADE makes that process scalable and accessible.
Phase three: audit and report card
Finally, ADE compiles and reviews every model it generates and routes any syntax errors back for self-correction. It then produces a report card that confirms whether the transformations laid out in the contract actually reflect a brand's reality. Sanity checks on the output keep a human in the loop before any of the data is trusted by the workflows downstream. The result is the same unified foundation for all of our customers, regardless of how their raw data arrived. All of our downstream analytics are built on this foundation.
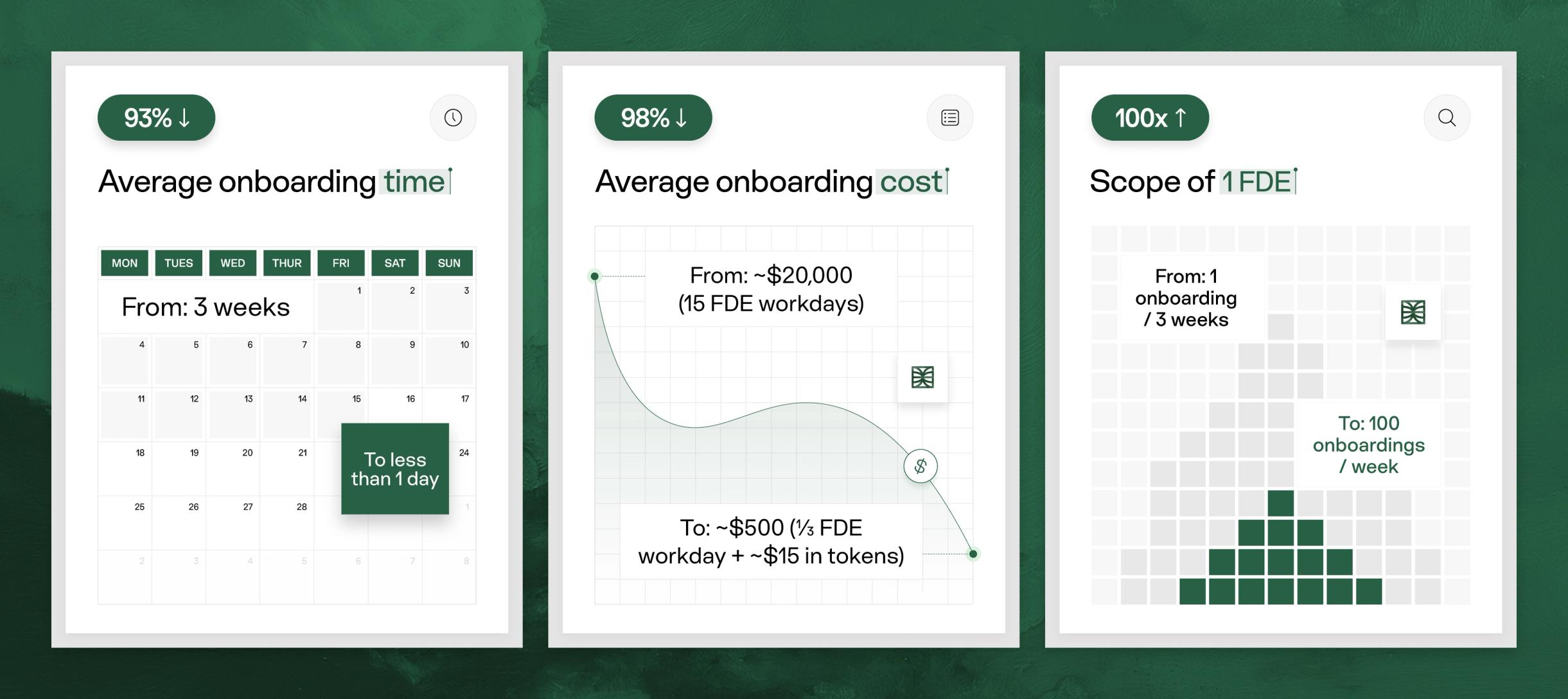
ADE fundamentally changes the economics of data standardization and unification. Producing golden records has historically taken a data engineering team weeks to month depending on the complexity of the brand. ADE compresses that process into a single run that finishes in an hour. Because runs are fully parallelizable, the only gate is a Forward Deployed Engineer reviewing the output, and since that review is a sanity check rather than hands-on modeling, one FDE can now oversee ~20 deployments at once.
Compared to one data engineer per deployment, ADE creates a ~1000x increase in throughput per engineer.
Agentic Data Scientist
Our clients have different customer funnels, with products, events and milestones all unique to each business. But every client wants to answer the same questions: who should I prioritize, why and how? Just like no two clients have the same data schema, no two funnels look alike.
The Agentic Data Scientist (ADS) is one of Minerva’s downstream agentic workflows built directly on top of the unified behavioral signal created by ADE. Our clients can provide a plain-English question and ADS answers it by building a robust analytics pipeline in less than 20 minutes. ADS automates dataset creation, quality control and model training that would otherwise take a team of talented (and incredibly well paid) data scientists days or weeks to develop.
In 20 minutes, a marketer receives a model that produces well calibrated answers to questions like:
- Who is most likely to churn among all leads?
- Who is most likely to spend more than $100?
- Who is most likely to book a beachfront property?
- Among past buyers, who is most likely to buy again?
- Who is most likely to have a no-show after booking a demo meeting?
Importantly, models can be developed in parallel for any question a user asks. ADS democratizes access to high-quality data science at scale.
What ADS does for brands
The strength of ADS is the range of questions it can handle. A question that sounds simple on the surface, like "who is most likely to churn" or "who is going to renew?", hides many decisions about what you actually mean and what data could possibly answer it. The best answer is not an ad-hoc analysis, but a robust, carefully trained model that produces a calibrated probability. ADS builds these models on-demand.


Modeling who is going to churn, renew or purchase a specific product are each very different analyses, but ADS is dynamic enough to solve them all: it deciphers the question using the client's own data, defines the population and the outcome, and trains a model that scores every lead. Here's what that looks like across three common cases:
Product purchase model: A brand with thousands of products asks who is likely to buy a particular item, say, running shoes. The challenge is that "running shoes" doesn’t exist as a clear field in their catalog. ADS first determines which specific products qualify, then trains a model that ranks every customer by how likely they are to buy any qualified product.
Funnel-conditioned model: A brand wants to predict the next step in the funnel for a specific group, such as people who already booked a demo. ADS restricts the training data to exactly that group before modeling anything, so the scores reflect what separates converters from non-converters within that population.
Churn or renewal model: A brand wants to know who will cancel or renew. There's no "churned" label in the data, so ADS first defines what leaving or renewing looks like in the client's own behavioral signals (lapsed activity, subscription end dates, declining usage), then trains a model that scores each customer against that definition.
In every case the output is the same: a model that scores and ranks an audience by the likelihood of a specific outcome, ready to be applied to live data. Those audiences can also be enriched with Minerva's 270mm person consumer graph to extend predictions beyond known customers.
How it works
ADS builds a prediction pipeline from a plain-English question in three steps.
Phase one: requirement discovery and planning
ADS connects to the standardized tables produced by ADE and takes stock of what exists: which people, product, event and attribution models it has to work with. A planning agent then turns the natural-language request into a contract with three parts: who is eligible to be scored, what counts as a positive outcome and over what time horizon. Everything else ADS does exists to fulfill that contract. If the question can't be answered from the data the client already has, the agent marks it infeasible and stops rather than fabricating an answer.
Phase two: point-in-time dataset creation
This is where the contract becomes a dataset that regression models can train on and be evaluated against. It breaks into four sub-steps that work together to guard against data leakage, where a model is accidentally exposed to information it would not have had at prediction time. If something cannot be resolved, the agent will ask for clarification (in cases where the agent can’t resolve a request because of ambiguity), or reject the request because the data cannot support the model.
- Product resolution. A client with a large catalog might want to know "who will buy Chinese food" across thousands of products with free-text descriptions. A scoping subagent reads the catalog and performs semantic classification on it, deciding which products count. That decision defines the positive outcome the model is trained to predict.
- Cohort resolution. For questions that naturally condition on a subset of leads, like "people who booked a demo," ADS works through the behavioral event data and filters the dataset down to leads at that particular stage of the client's funnel
- Feature selection. ADS enriches the client's own first-party behavioral signals with third-party data from our data lake, then selects the subset of features from that combined pool that are genuinely relevant to the outcome being modeled
- Target creation. Finally, ADS writes the SQL that defines what a "yes" means for the client's question, turning complex behavioral funnel data into the prediction target. That target can express a product conversion, a churn event, another client-specific funnel event or a combination of them
Together, these steps produce a dataset that describes each lead exactly as it stood at each moment in the past, so the training data mirrors precisely what the models will see at inference time on live data.
Phase three: model training and evaluation
With the dataset in hand, ADS trains a model that scores every lead. A holdout set is kept aside for evaluation metrics that sanity-check how well the model is performing.
What they mean together and where we go next
Together these two agentic systems remove two of the biggest bottlenecks in applying AI to real customer data at scale: preparing the data and building models from it, all while respecting the nuances and business specifics of each client.
ADE and ADS are just the start: Minerva is actively building more agentic systems to accelerate and democratize data workflows to deliver insights that would otherwise take weeks of effort from a team of specialists. With our agentic systems, a marketer or operator can simply ask a question and get an answer without depending on a dedicated data team.
If you want to work on these types of problems, we're hiring across all functions.

